Python公开课 - 爬虫介绍
前言
什么是爬虫,爬虫其实就是一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
在数据挖掘、搜索引擎中都有爬虫的身影。尤其是对于网站站长来说,对爬虫是又爱又恨。
爱的原因是由于如果爬虫不来抓取内容,网站就没办法被搜索引擎索引,用户也就没办法可以检索到。
恨的原因在于如果网站性能一般,爬虫的高并发大量抓取会消耗网站的资源,导致响应变长,甚至无法服务。
爬虫的架构
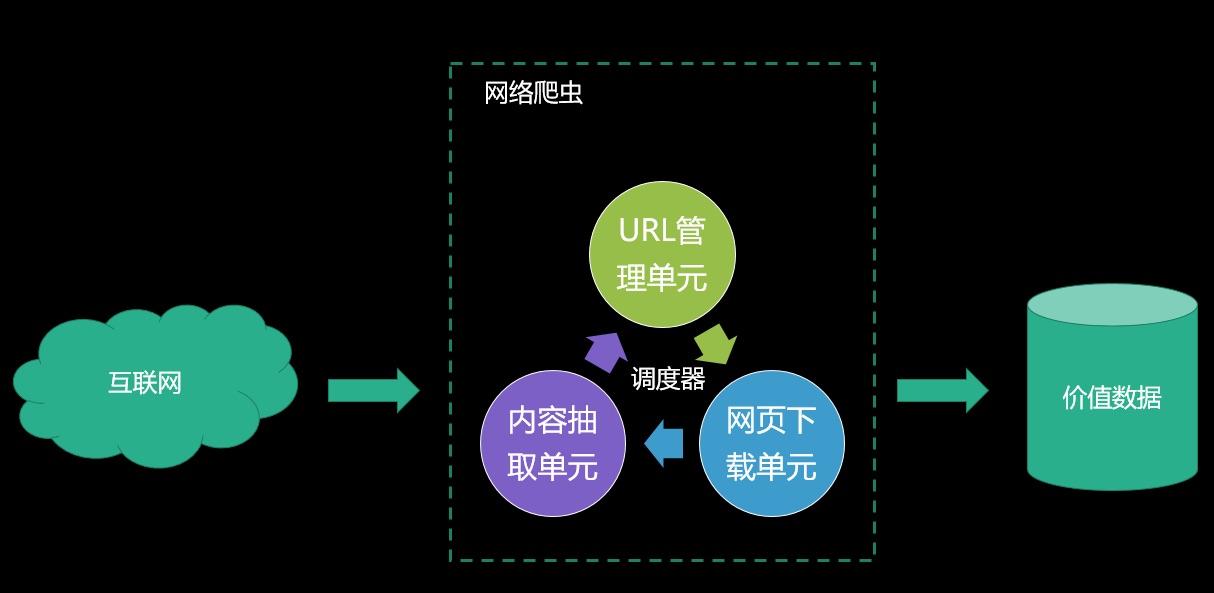
一般来说,爬虫分为通用性爬虫和垂直爬虫,相比而言通用性爬虫技术含量会更高一些。
但不管怎么说,爬虫都会由以下几个模块组成:
- 链接URL管理单元 - 包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL
- 网页抓取单元 - 通过传入一个URL地址来下载网页,将网页转换成一个字符串
- 内容抽取单元 - 将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息。
- 调度器 - 相当于协调员,包括如何选取URL,什么时候以什么频率来抓取并将网页内容交给抽取单元
- 应用 - 将获取的有价值的内容,如何进行展现
为什么选择Python开发爬虫
python是一门非常容易上手的解释型语言,还有大量的第三方类库,使用起来非常方便。人生苦短,快用python。
相关阅读
相关主题: