前言
由于目前互联网上HTTP协议的普遍性,所以我们写爬虫一般都会和HTTP协议打交道,当然也有其他协议的爬虫,如磁力链爬虫等则是处理另外的协议了。
URL
URL的全称是 Universal Resource Locator,即统一资源定位符。如果大家讲互联网理解为一个操作系统,那么互联网上的页面、资源可以理解磁盘上的文件,每个文件都有一个绝对路径,那么这个路径就是URL。
超文本
超文本英文名称叫作 hypertext,从词根来看就是一些很丰富的文本,因为通过浏览器,我们可以将超文本中的内容,显示为文本、音乐和视频。
HTTP与HTTPS
HTTP 的全称是 Hyper Text Transfer Protocol,中文名叫作超文本传输协议。 HTTP 协议是用于从 网络传输超文本数据到本地浏览器的传送协议,它能保证高效而准确地传送超文本文档。 HTTP 由万维网协会( World Wide Web Consortium )和 Internet 工作小组 IETF ( Internet Engineering Task Force ) 共同合作制定的规范,目前广泛使用的是 HTTP 1.1 版本。
HTTPS 的全称是 Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版, 即 HTTP 下加入 SSL 层,简称为 HTTPS。
HTTP请求响应过程
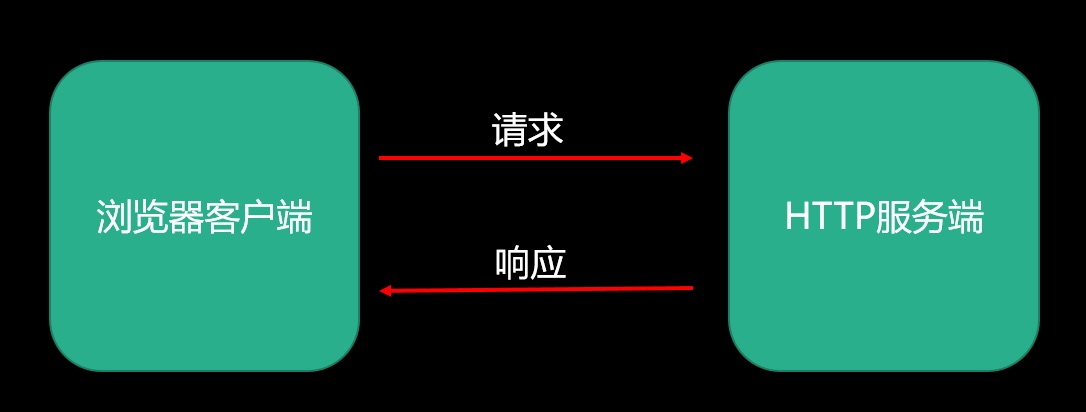
我们在浏览器中输入一个 URL,回车之后便会在浏览器中观察到页面内容。 这个过程是 浏览器向网站所在的服务器发送了一个请求,网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。 响应里包含了页面的源代码等内容,浏览器再对其进行解析渲染,便 将网页呈现了出来。
HTTP协议
基本协议分为请求和相应:
请求
也就是浏览器要告知对应的服务器,我要哪些资源:
- 请求方法 - 常见的是get和post, 打卡一个页面一般是get请求,而提交表单或上传文件则通常是post了
- 请求地址 - 也就是URL,它可以确定我们需要的资源
- 请求头 - 请求头,用来说明服务器要使用的附加信息,比较重要的信息有 Cookie、 Referer、 User-Agent等。
- 请求体 - 请求体-般承载的内容是 POST请求中的表单数据,而对于 GET请求,请求体则为空。
响应
响应,由服务端返回给客户端,可以分为三部分:响应状态码( Response Status Code )、响应头 ( Response Headers )和响应体( Response Body ):
- 状态码 - 响应状态码表示服务器的响应状态,如 200 代表服务器正常响应, 302重定向,404 代表页面未找到,403未授权, 500代表服务器内部发生错误
- 响应头 - 响应头包含了服务器对请求的应答信息,如 Content-Type、 Server、 Set-Cookie等。
- 响应体 - 重要的当属响应体的内容了。 响应的正文数据都在响应体中,比如请求网页时,它的响应体就 是网页的 HTML 代码; 请求一张图片时, 它的响应体就是图片的二进制数据
小结
在做爬虫时,我们主要通过响应体得到网页HTML内容,或者二进制数据, 然后从中做相应内容的提取。
相关阅读
- 上一篇 Python爬虫教程 - 爬虫介绍
- 下一篇 Python爬虫教程 - 网页结构