Python Selenium find_element_by_css_selector 如何处理多个class
前言
Selenium是一个用于Web应用程序测试的工具,也可以在网页爬虫中使用。Selenium直接运行在浏览器中,就像真正的用户在操作一样。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
主要功能包括:
- 测试与浏览器的兼容性,测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上
- 测试系统功能,创建回归测试检验软件功能和用户需求。
- 支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本
问题 - 如何抽取今日头条新闻链接
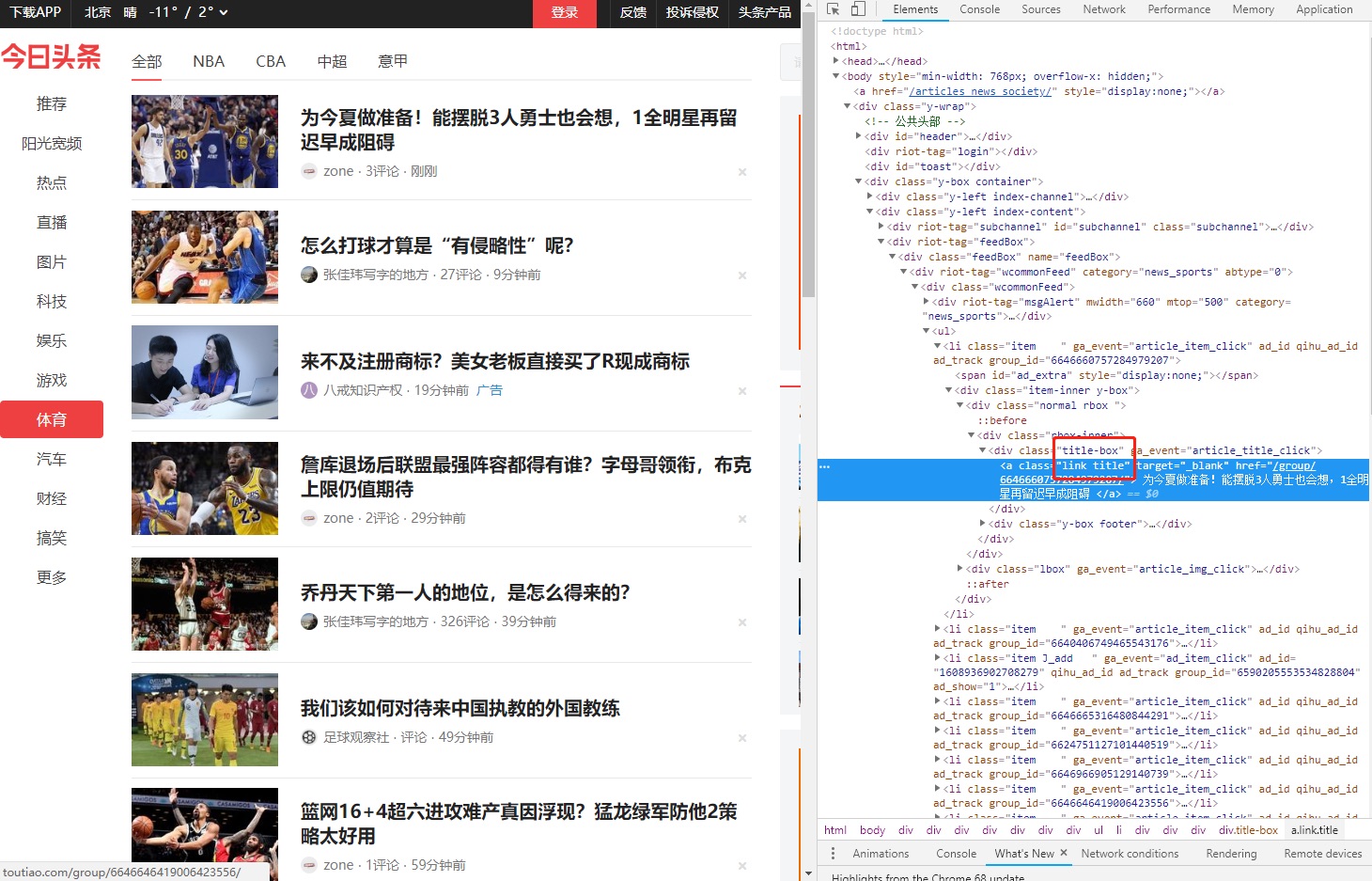
上面是截取的今日头条网站的截图,
可以看到,今日头条的新闻很丰富,我们选择的是体育频道,那么
如果我想要抓取今日头条体育新闻的链接,该如何做呢?
答案
首先,我们可以查看页面的html代码
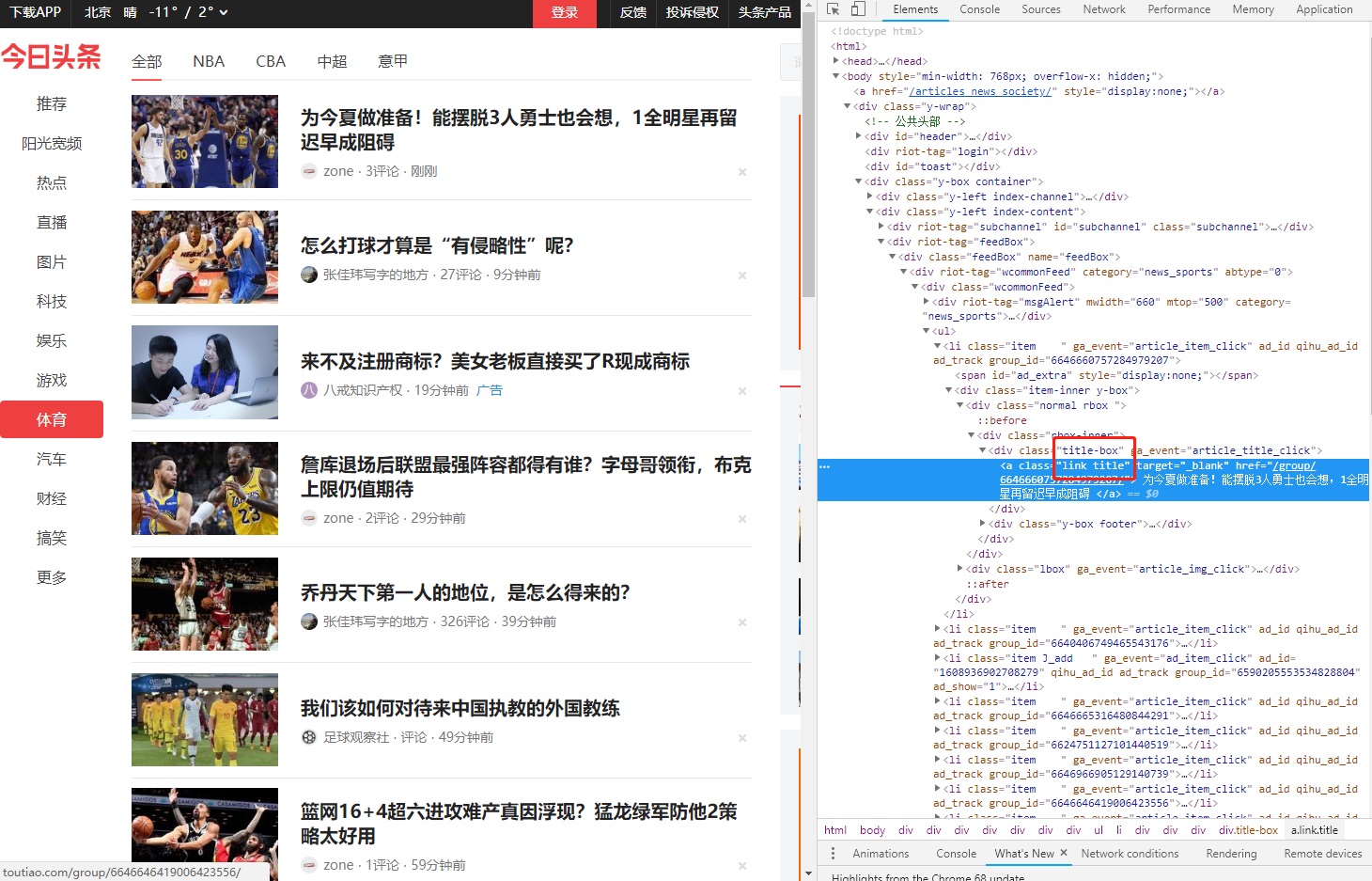
分析看到页面源码,所有的链接的class都是link title,这个是很好的标记。
selenium的官方文档可以通过find_element_by_css_selector来定位元素,例子如下:
content = driver.find_element_by_css_selector('p.content')
但是按照头条这样class中有空格,换句话说,有多个样式该怎么办呢?
这时候,我们可以通过下面这种方法来定位:
content_list = driver.find_elements_by_css_selector("a.link.title")
通过以上代码,就搞定了今日头条的新闻链接的定位了,结果如下:

完整代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.binary_location = '/usr/bin/google-chrome'
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
driver = webdriver.Chrome(executable_path='/opt/dev/crawler/chromedriver', chrome_options=options)
driver.implicitly_wait(5)
driver.get("https://www.toutiao.com/ch/news_sports/")
content_list = driver.find_elements_by_css_selector("a.link.title")
for i in content_list:
content_url = i.get_attribute('href')
title = i.text
print(content_url, title)
相关主题: