Python实战 - 爬虫代理IP池的实现
爬虫为什么要使用代理来访问
大家写爬虫程序的时候,当抓取频率较快或者抓取一些robots.txt禁爬路径,肯定会碰到被网站屏蔽的情况,这时候目标服务器要么直接返回404,要么就是返回禁止的提示信息,总之就是爬虫失效了(抓不到你想要的内容)。
如果遇到这种情况,对应小型爬虫来说,最简单经济有效的方式,就是通过代理来反问。
基本概念
代理IP池其实就是一堆可以用来做代理访问的Pool,作为Service Provider它对外提供可用的代理ip及端口。
代理IP从隐藏级别上分三类:
- 透明代理,服务器知道你用了代理,但同时也知道你的真实IP,说白了是不以隐藏自己IP为目的使用的,比如翻墙什么的
- 普通代理,服务器也知道你用了代理,但不知道你的真实IP
- 高匿代理,服务器不知道你用了代理,更不知道你的真实IP
其中高匿代理指代理服务器不向目标服务器传递X_FORWARDED_FOR变量
Python的实现方式
- 设计思路和原理
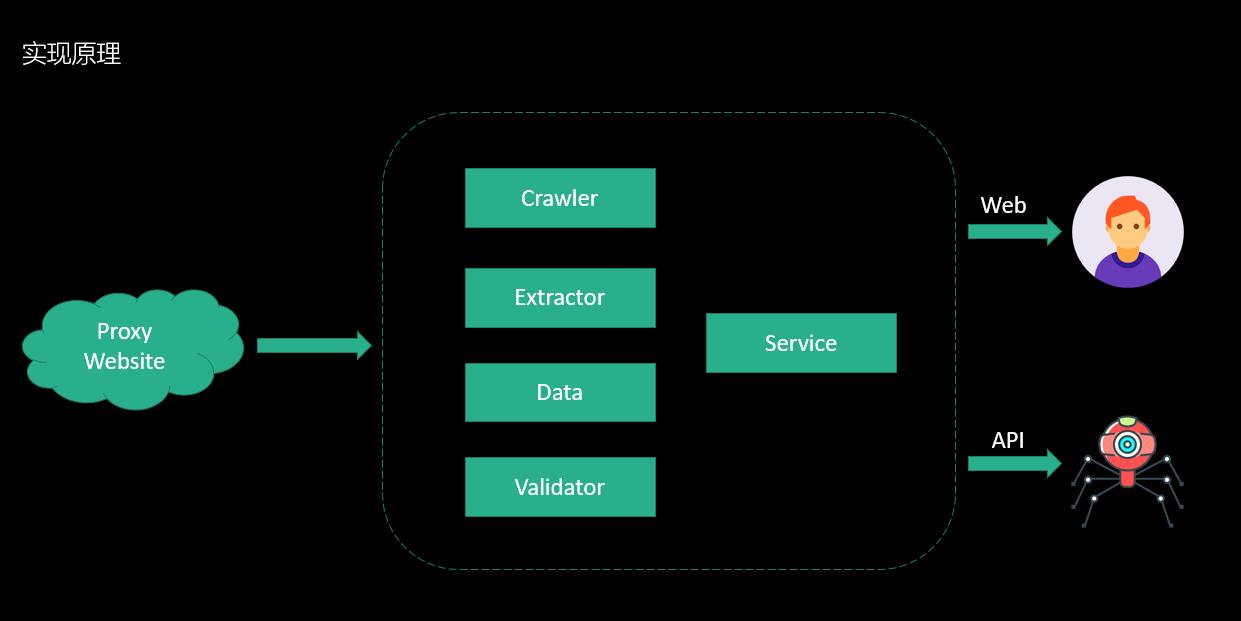
基本思路就是从目前提供代理服务的网站获取可使用的IP、端口、代理类型信息,并检测可用性,然后对外提供服务。
- 功能模块
- ProxyWebsite - 目标抓取的代理服务网站
- Crawler - 抓取模块,通过HTTP来抓取定向代理服务网站内容
- Extrator - 抽取模块,将HTML页面内容,抽取成结构化数据
- Data - 数据模块,为结构化数据存储服务
- Validator - 检验模块,检查代理的可用性
- Service - 对外提供REST API服务
核心代码实现示例
- ProxyWebsite
class ProxyWebsite(object):
def __init__(self, url, pattern, ip_pos, port_pos):
self.url = url
self.pattern = pattern
self.ip_pos = ip_pos
self.port_pos = port_pos
- Crawler
class Crawler(object):
@staticmethod
def get_html(proxy_website):
try:
rsp = requests.get(proxy_website.url)
return (0, rsp.text)
except Exception as e:
return (-1, e)
- Extrator
class Extractor(object):
@staticmethod
def get_data(proxy_website, html):
try:
pattern = re.compile(proxy_website.pattern, re.M|re.S )
return map(lambda x:(x[proxy_website.ip_pos], x[proxy_website.port_pos]), pattern.findall(html))
except Exception as e:
return (-1, e)
- Data
class Data(object):
def __init__(self, ip, port, http_enable, https_enable):
self.ip = ip
self.port = port
self.http_enable = http_enable
self.https_enable = https_enable
- Validator
class Validator(object):
@staticmethod
def get_baidu(ip, port):
try:
proxies = {'http': 'http://%s:%s' %(ip, port), 'https': 'http://%s:%s' %(ip, port)}
http_valid_result = False
rsp = requests.get('http://www.baidu.com', proxies = proxies, verify=False, timeout=(10, 60))
if rsp.status_code == 200:
http_valid_result = True
rsp = requests.get('https://www.baidu.com', proxies = proxies, verify=False, timeout=(10, 60))
if rsp.status_code == 200:
https_valid_result = True
return (0, (http_valid_result, https_valid_result))
except Exception as e:
return (-1, e)
- Service 请移步 http://proxy.xtuz.net