Python公开课 - pyspider框架介绍
1. 前言
写网络爬虫程序,除了自己开发以外,也可以选择一些成熟好用的框架,当你熟悉好框架后,开发起来事半功倍,效率很高。今天要介绍的就是一个python下的pyspider框架。
2. pyspider基本介绍
pyspider是国人编写的强大的网络爬虫系统。采用Python语言编写,分布式架构,支持多种数据库后端,自带强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
具体来说有以下特点:
- 功能强大的WebUI,包括脚本编辑器,任务监视器,项目管理器和结果查看器
- 支持数据库丰富,包括MySQL、MongoDB、Redis、SQLite、Elasticsearch
- 可以选用RabbitMQ,Beanstalk,Redis和Kombu作为消息队列
- 任务支持优先级、重试、定期、按时间重新抓取等
- 分布式架构
- 支持抓取Javascript等动态渲染页面
- 支持Python2和3等
3. pyspider系统架构
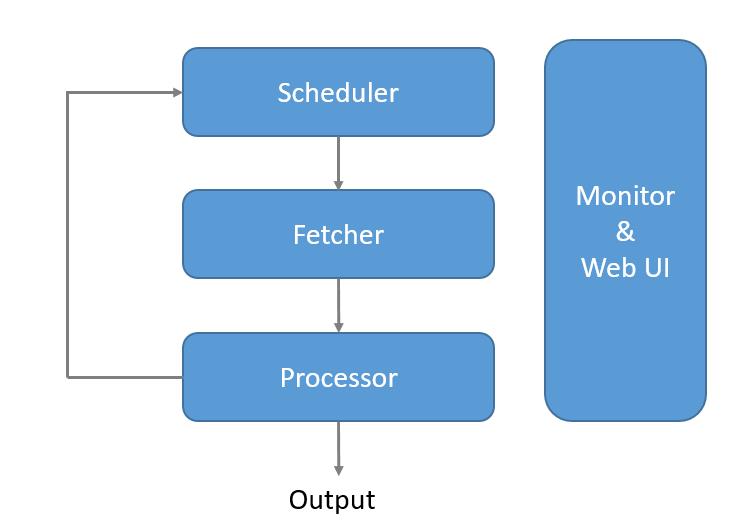
pyspider的系统架构图如下:
| 模块 | 功能说明 |
|---|---|
| scheduler | 调度器,设定任务优先级,周期定时任务,流量控制,基于时间周期或前链标签抓取策略 |
| fetcher | 抓取器,支持dataurl,可以通过适配类似phantomjs的webkit引擎支持动态渲染页面 |
| processor | 处理器,内置的pyquery,以jQuery解析页面,在脚本中完全控制调度抓取的各项参数,可以向后链传递信息,异常捕获 |
| webui | web的可视化任务监控,web脚本编写,单步调试,异常捕获,log捕获,print捕获等 |
4. pyspider执行流程
概括来说流程比较简单:
Scheduler发起任务调度,Fetcher负责抓取网页内容,Processer负责解析网页内容,然后将新生成的Request发给Scheduler进行调度,并将生成的提取结果输出保存。
具体来说分为以下几步:
- 每个pyspider的项目对应一个Python脚本,该脚本中定义了一个Handler类,它有一个
on_start()方法。 爬取首先调用on_start()方法生成最初的抓取任务,然后发送给Scheduler 进行调度。 - Scheduler 将抓取任务分发给Fetcher进行抓取,Fetcher 执行并得到响应,随后将响应发送给Processer。
- Processer处理响应并提取新的URL生成新的抓取任务,然后通过消息队列的方式通知 Schduler 当前抓取任务执行情况,并将新生成的抓取任务发送给 Scheduler。如果生成了新的提取结果,则将其发送到结果队列等待 Result Worker处理。
- Scheduler接收到新的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其发送回Fetcher进行抓取。
- 不断重复以上工作,直到所有的任务都执行完毕,抓取结束。
- 抓取结束后,程序会回调
on_finished()方法,这里可以定义后处理过程。
5. 相关阅读
相关主题: