机器学习 - 监督学习概述
前言
监督学习的目的是通过已经标记好的训练集(Training Set),构建模型,然后用训练得到的模型对未来数据进行预测。术语监督(Supervised),则是指每个训练数据中的每个样本都有已经人工做了标记。
应用场景
1. 对数据进行分类
分类是监督学习中的一个经典应用,通俗来讲就是根据样本的特征(离散、无序)进行类别区分。
以垃圾邮件为例:通过人工标记垃圾邮件和正常邮件,使用监督学习算法训练生成一个判定模型,用来判定一封新的邮件是否为垃圾邮件。
2. 回归预测连续输出值
在监督学习中另一个常用的场景就是对连续型输出变量进行预测,也就是回归分析。
例如将学生的学习时间和考试分数进行分析,我们认为学生的学习时间和考试分数是有关联的,那么就可以将它作为训练数据来训练模型,然后根据学习时间来预测考试分数。
监督学习常用算法
1. KNN近邻
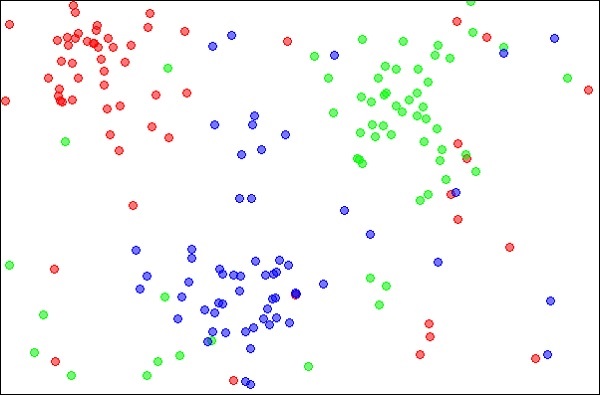
所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
2. 决策树
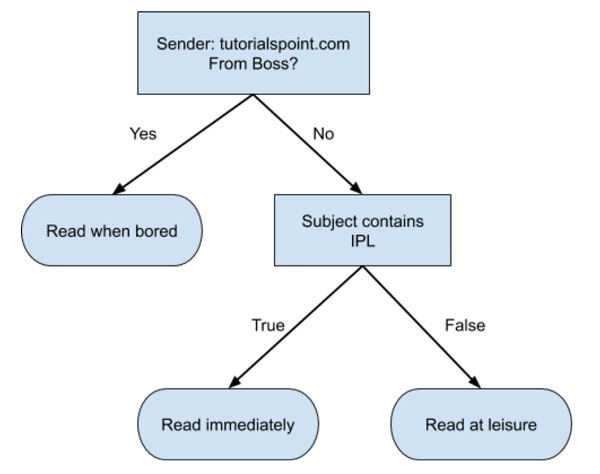
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
3. 朴素贝叶斯
贝叶斯方法是以贝叶斯原理为基础,使用概率统计的知识对样本数据集进行分类。由于其有着坚实的数学基础,贝叶斯分类算法的误判率是很低的。贝叶斯方法的特点是结合先验概率和后验概率,即避免了只使用先验概率的主管偏见,也避免了单独使用样本信息的过拟合现象。贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。
4. 逻辑回归
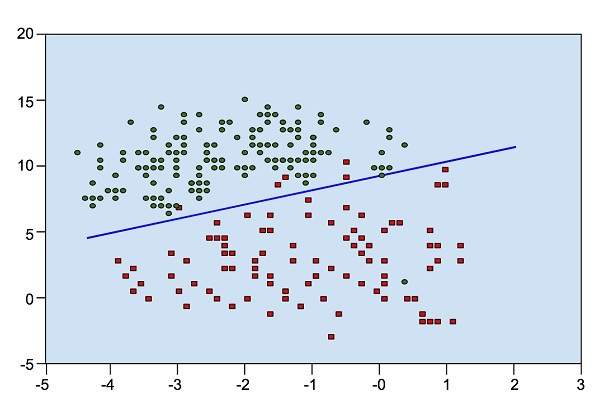
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。
5. SVM支持向量机
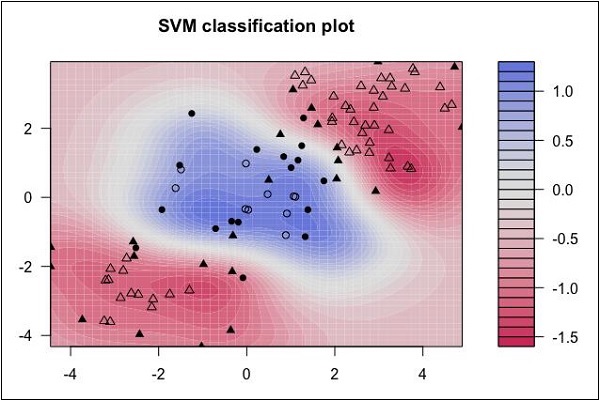
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面。