Python公开课 - pyspider基本使用
1. 前言
在上一章中我们对pyspider的架构和设计方法进行了介绍,接下来我们来看看如何使用
2. 安装pyspider
pyspider目前是GitHub上的开源项目,地址为:https://github.com/binux/pyspider
我们可以通过pip来进行安装
sudo pip3 install pyspider
3. 启动pyspider
在命令行界面输入以下命令:
pyspider all
运行效果如图所示:
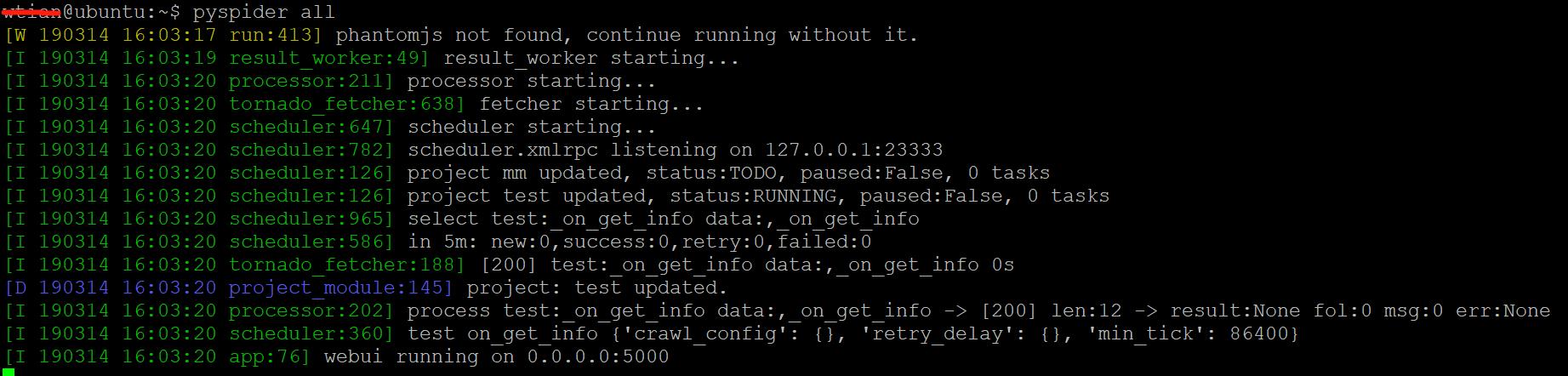
成功运行后,即可在默认的5000端口查看pyspider的Web UI界面

该页面便是pyspider的WebUI,我们可以用它来管理项目、编写代码、 在线调试、 监控任务等。
4. 创建项目
新建一个项目,点击右边的 Create按钮,在弹出的浮窗里输入项目的名称和爬取的链接,再点击 Create 按钮,这样就成功创建了一个项目
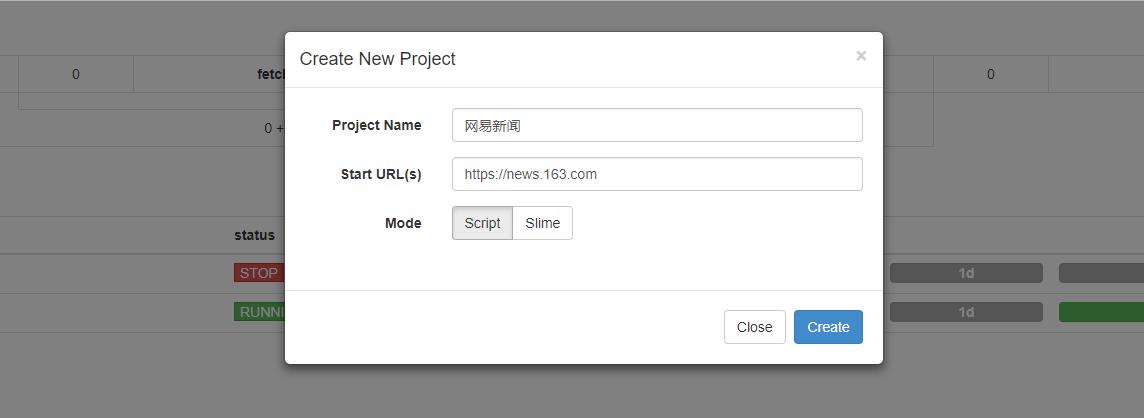
注意:项目名不能是中文哦,会报错
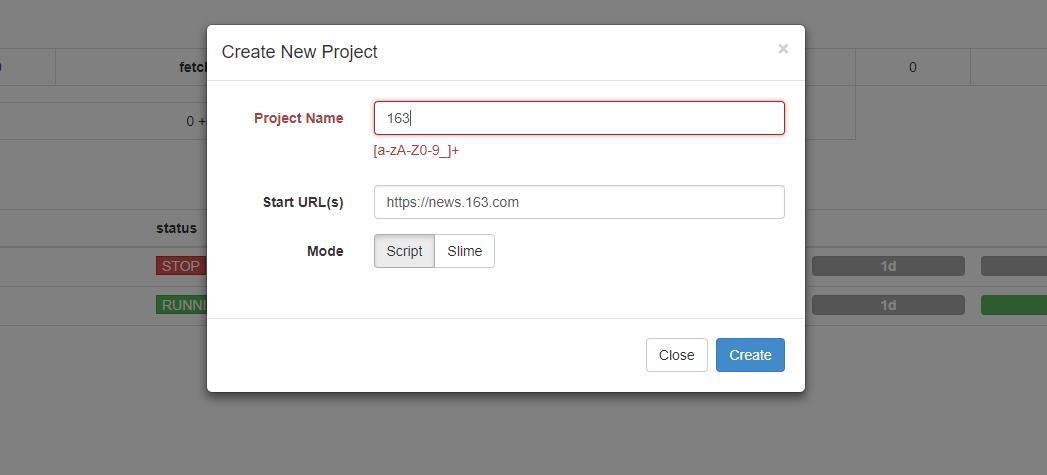
这里我们以抓取网易新闻为例
5. 编辑项目
接下来会看到 pyspider 的项目编辑和调试页面
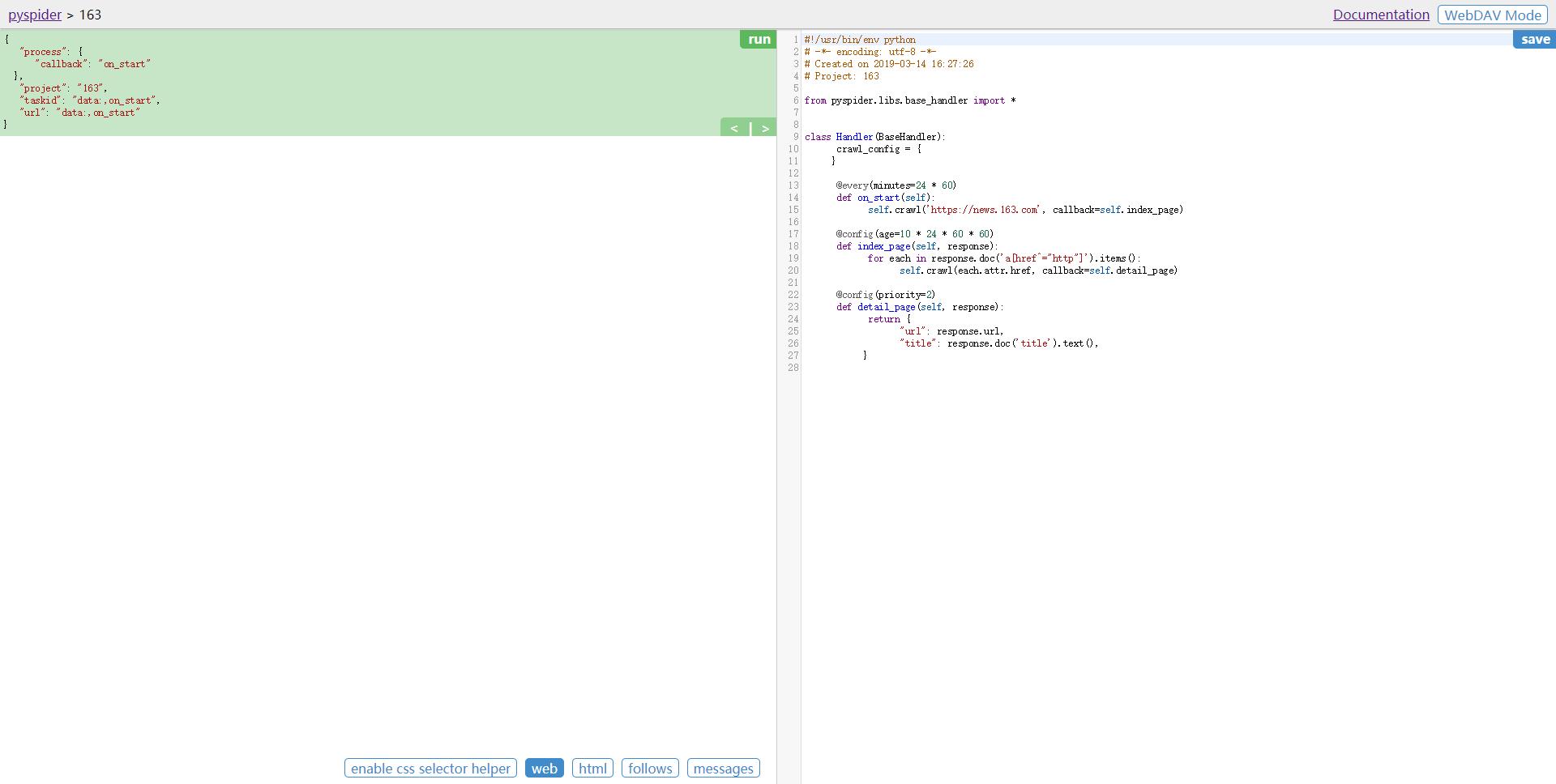
左侧就是代码的调试页面,点击左侧右上角的 run按钮可以单步调试爬虫程序,在左侧下半部分可以预览当前的爬取页面。 右侧是代码编辑页面,我们可以直接编辑代码和保存代码。
右侧的代码就是核心代码了,我们可以在此处定义爬取、 解析、存储的逻辑。 整个 爬虫的功能只需要一个Handler即可完成。
自动生成的代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-03-14 16:27:26
# Project: 163
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://news.163.com', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
代码详解:
- crawl_config - 将本项目的所有爬取配置统一定义到这 里,如定义 Headers、设置代理等,配置之后全局生效。
- on_start() - 是爬取入口,初始的爬取请求会在这里产生。
- index_page() - 接收这个抓取结果的Response 参数。
- detail_page() - 同样接收Response 作为参数。
detail_page()抓取的就是详情页的信息,就不会生成新的请求,只对 Response对象做解析,解析之后将结果以字典的形式返回。
6. 抓取索引页
点击左栏右上角的run按钮,即可看到页面下方follows便会出现一个标注,其中包含数字 l ,这代表有新的爬取请求产生。
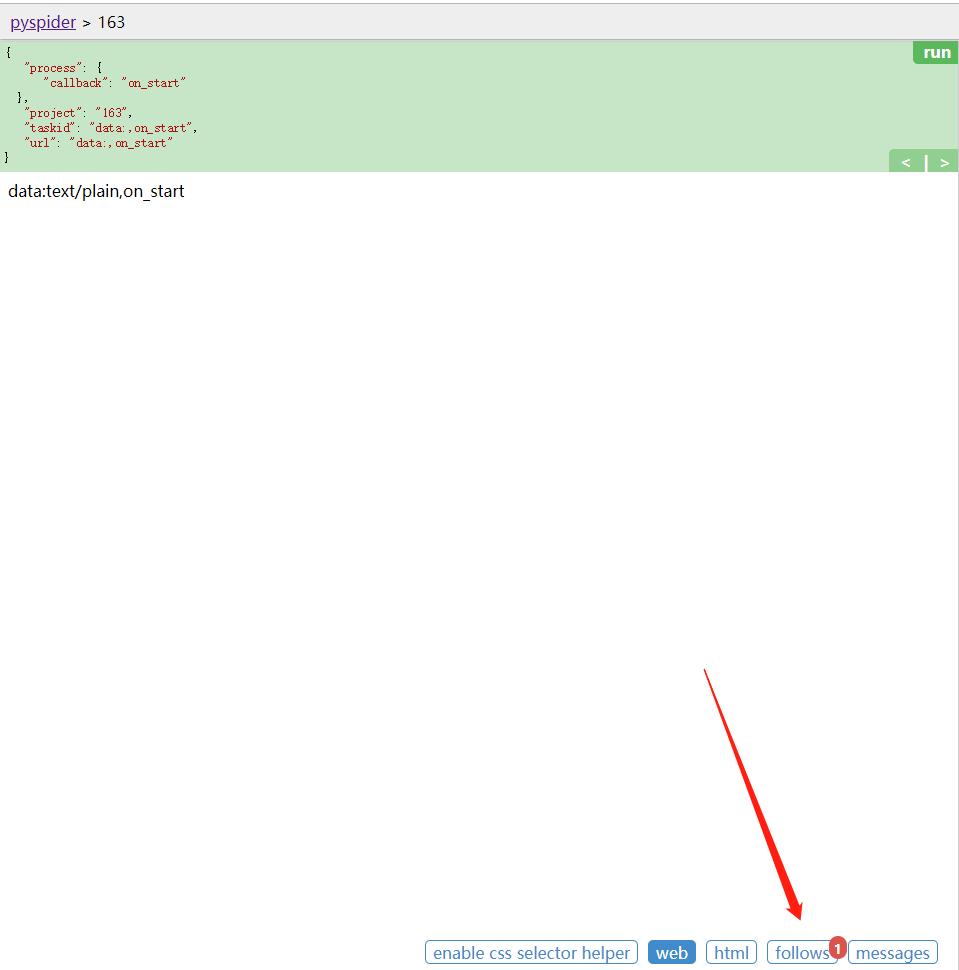
点击下方的follows按钮,即可看到生成的爬取请求的链接。
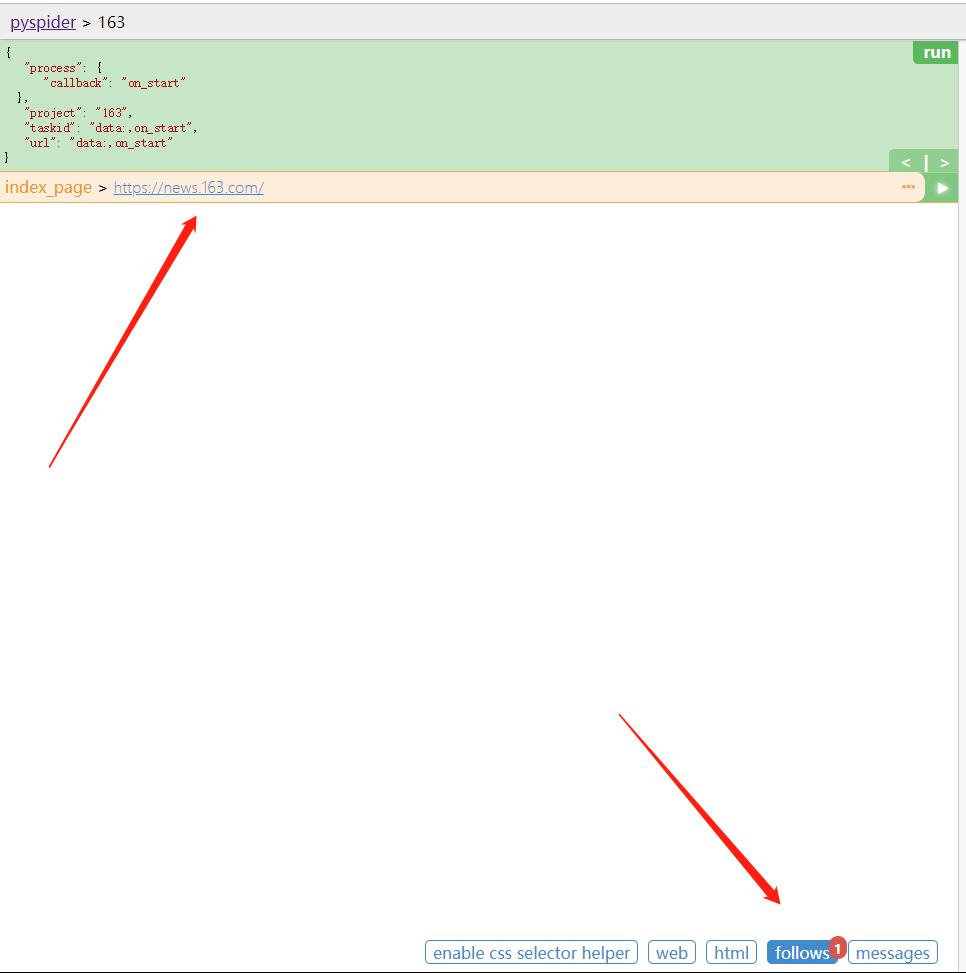
点击链接右侧的箭头按钮,即可进行页面的抓取。
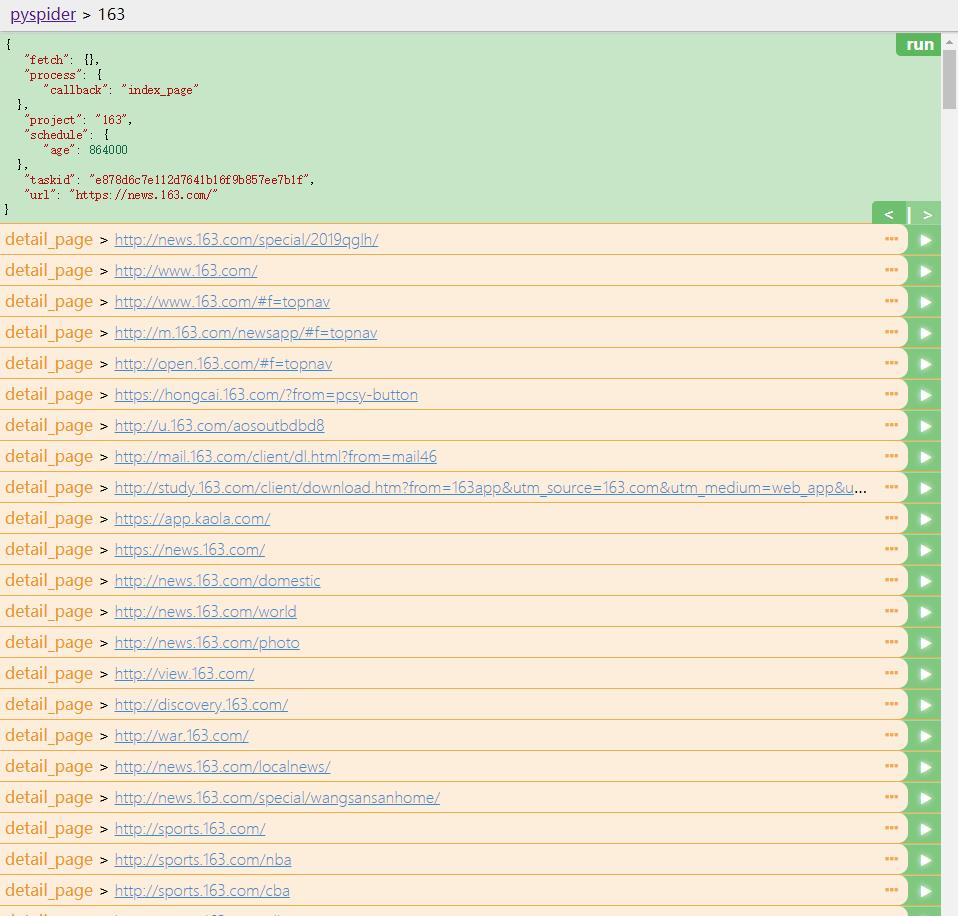
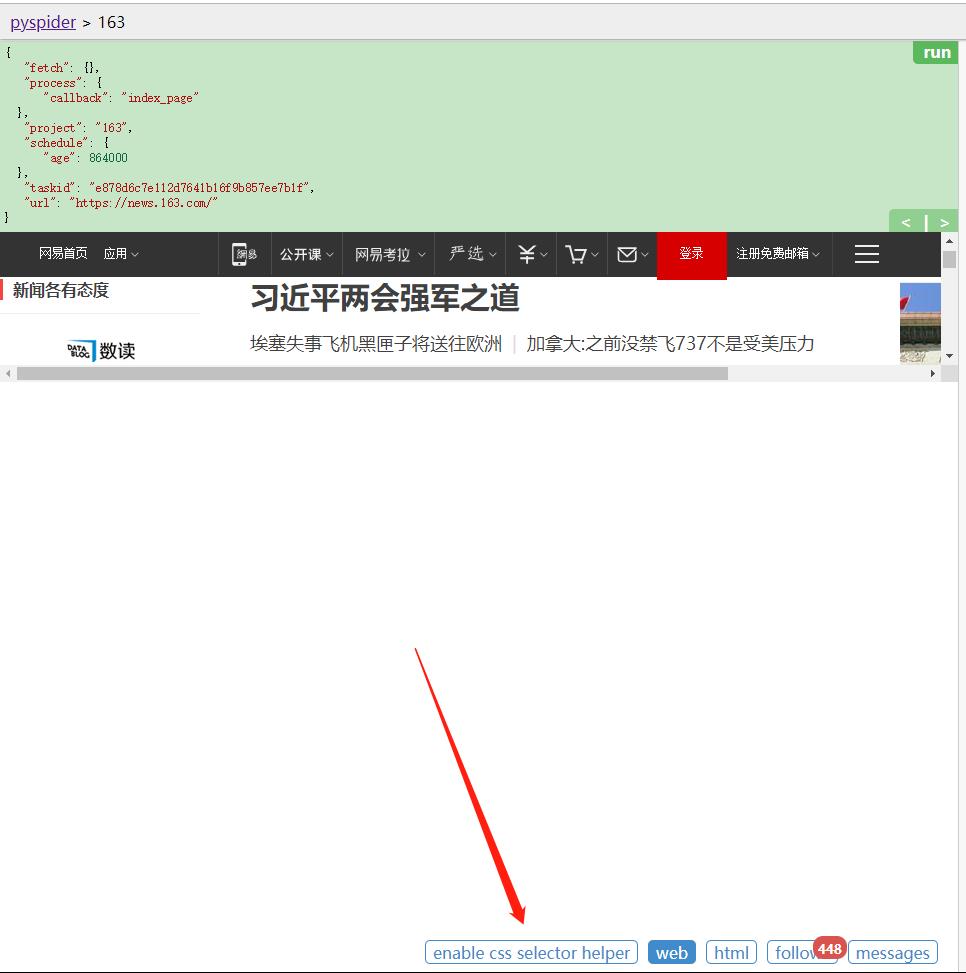
上方的 callback 已经变成了 index_page,这就代表当前运行了index_page()方法,这里未做链接过滤,所以把页面的链接都提取了出来。我们可以在index_page()中编写逻辑来处理。可以借助工具来实现,切换到web界面,然后点击下方的enable css selector helper。
在右侧代码选中要更改的区域,点击左栏的有箭头,此时在上方出现的标题的 css 选择器就会被替换到左侧代码,这样就成功完成了 css 选择器的替换,非常便捷。
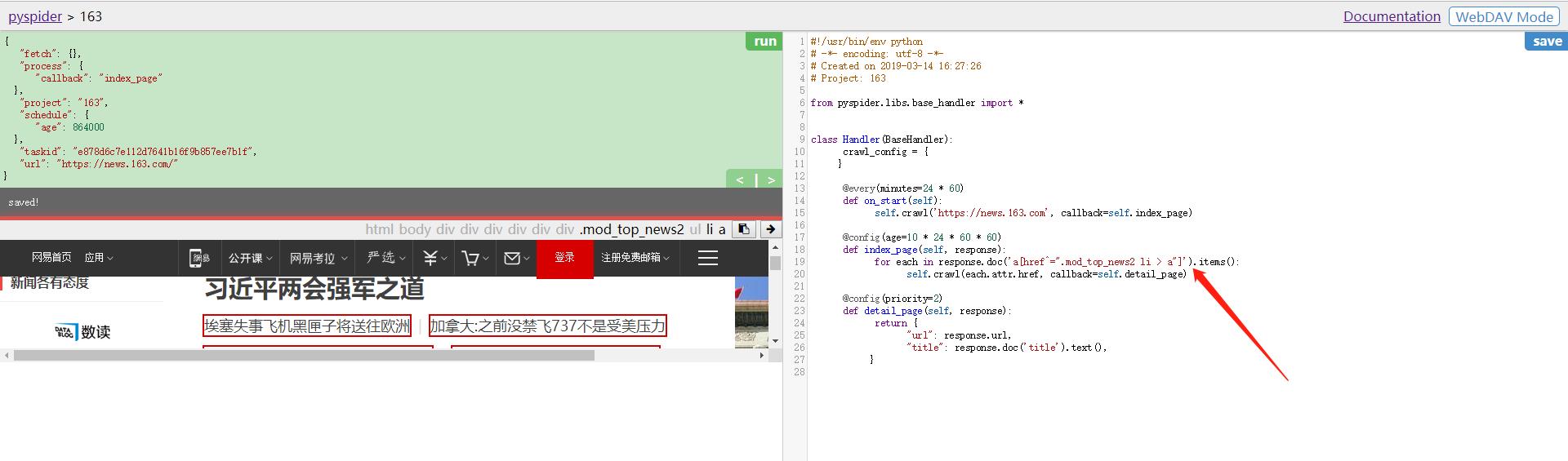
重新点击左栏有上角的 run 按钮, 即可重新执行index_page()方法。 经过过滤后,效果如下:
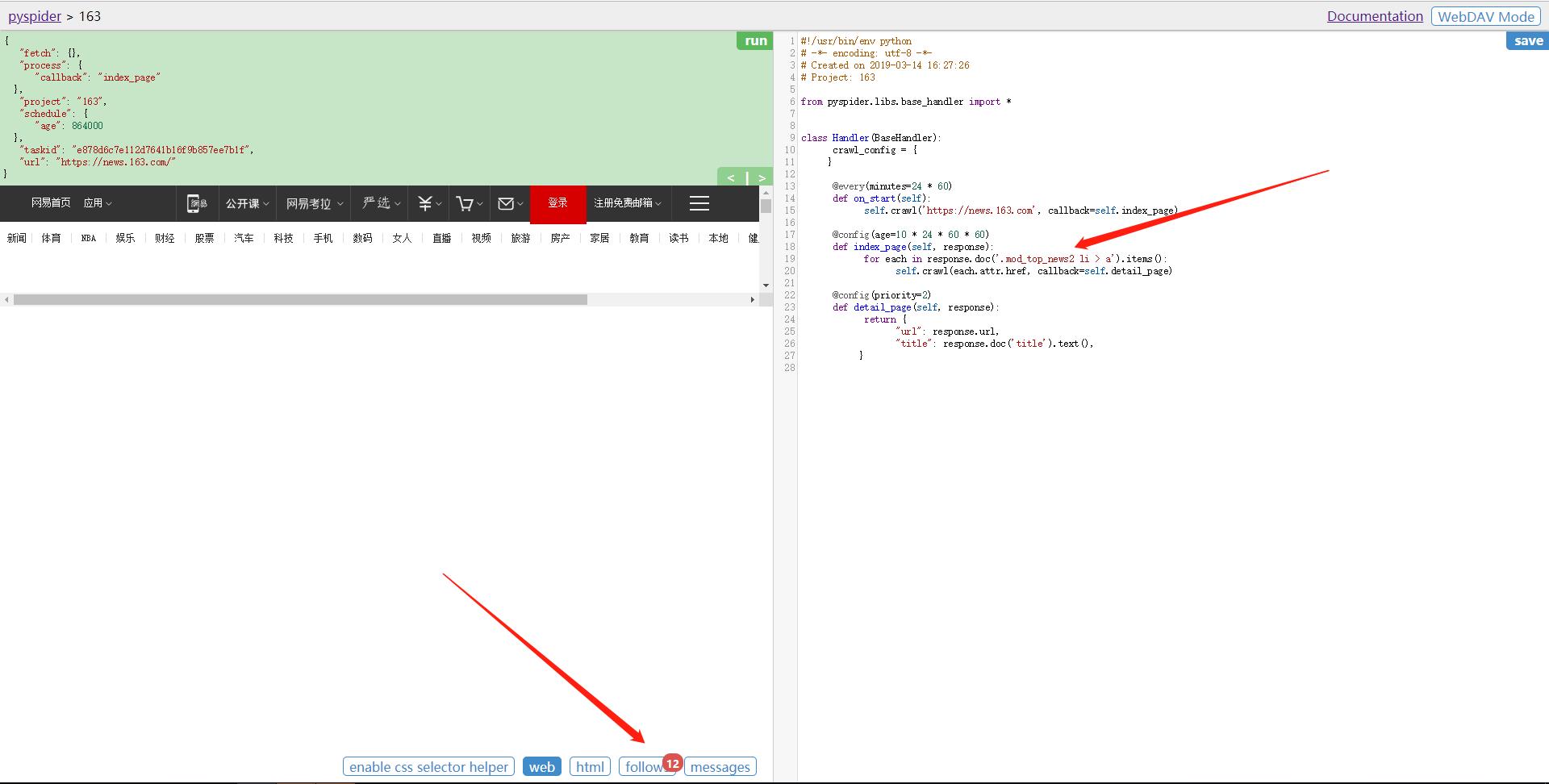
7. 抓取详情页
任意选取一个详情页进入,点击箭头,执行详情页的爬取。但是没有看到内容,这个是由于该页面的产生是由JS生成的,我们需要将fetch_type改为js即可
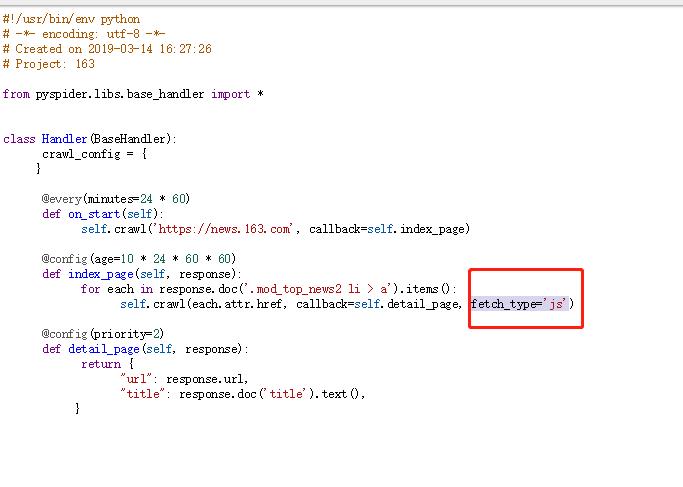
进行选取想要的内容,即可完成
效果如下:
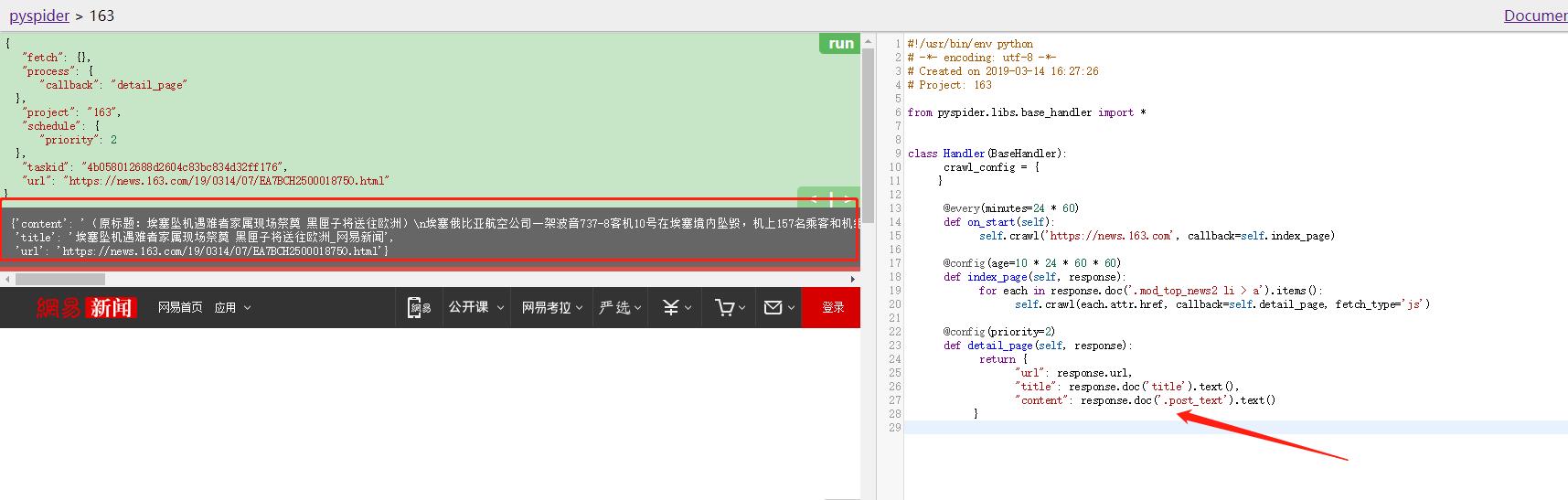
左栏中输出了最终构造的字典信息, 这就是一篇新闻的抓取结果。
8. 启动爬虫
返回爬虫的主页面,将爬虫的 status 设置成 DEBUG 或 RUNNING,点击右侧的 Run 按钮即可开始爬取。
